只是一个学生浅显的收集信息,然后应用到最近一个啥都没优化的小游戏之后写的笔记
认识组件
要做各种意义上的优化要借助下三个unity视窗,unity优化离不开这些,甚至可以说优化就是试着减小上面视窗各字段的大小;
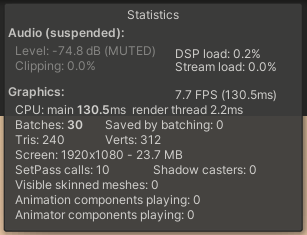
Stats
Frame Debugger
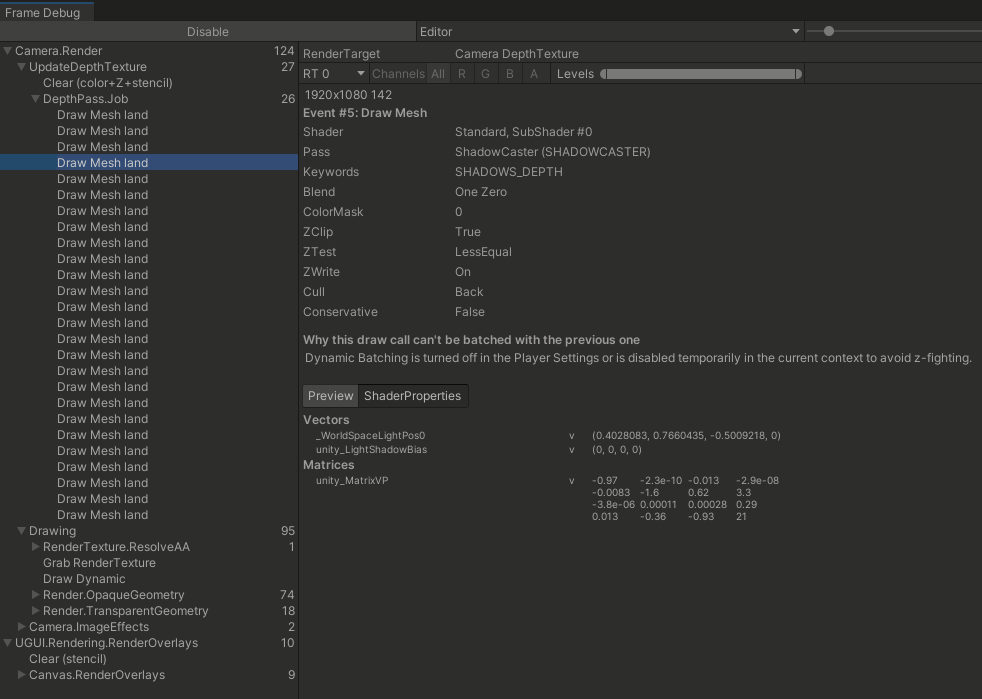
Frame Debugger展现了每一帧是如何渲染的,以及各种细节,如深度测试,每次drawcall以及未能合批的原因等等内容。
引:[FrameDebugger描述](从FrameDebugger看Unity渲染_unity render frame_Clank的游戏栈的博客-CSDN博客)
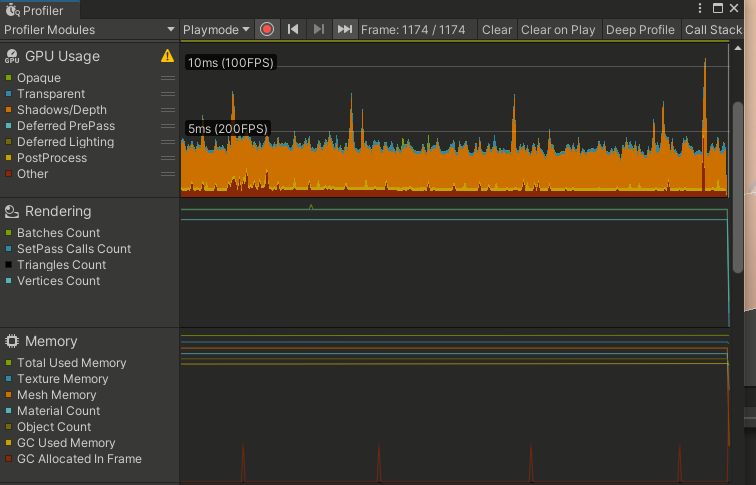
Profiler
认识一些概念
DrawCall
SetPassCall
OverDraw
Catch命中率
时空间复杂度
pass
GC
好,你已经全认识了,嘻嘻
认识一些方法
当我们谈论优化方法时,我们会谈论什么?
优化这个概念可太宽泛了。。。。
性能
渲染
减少drawcall和合批技术
引:[合批技术介绍]([Unity游戏开发]合批优化汇总 - 知乎 (zhihu.com))
图形渲染及优化—Unity合批技术实践-腾讯游戏学堂 (tencent.com)
这里记录一下UGUI的合批规则
Canvas之间不能合批
进行合批准备工作:
遍历单个canvas下所有附带Renderer的ui组件,统计该组件 覆盖/交叠 底于该层级renderer的数量”depth”,以此得到了一个分组
Renderers[Depth[i]]依次遍历
Renderers[depth],再按照材质-贴图的顺序进行排列。
开始合批:遍历
Renderers[Depth[i]],以一维数组展开,判断其下一个Renderer能否与其合批。
减少Overdraw
选用适合的渲染管线
光照
- 尽量少用实时光,用烘培后的光照贴图,反射探针,光照探针来减少实时光的应用频率
- 阴影模式选择
摄像机
- virtual camera
- 克制的使用后处理
- 相机剔除和LOD技术
mipmap内存换性能
算法
时空间复杂度优化
如四叉树技术,又比如根据需求选择恰当的寻路算法,排序等等
避免主线程某段时间内过于密集的计算
分帧算法如incremental GC,异步实现,预处理等等
削弱GC,减少垃圾内存分配
tricks很多,直接开引:GC介绍及优化
ECS
物理模拟
增加物理帧的频率
选择恰当的刚体碰撞模拟算法
消耗对比
Discreate < Continuous Speculative < Continuous < Continuous DynamaticLayer间的物理检测矩阵设置
内存
图形数据
以下图Profiler Rendering Debugger为例
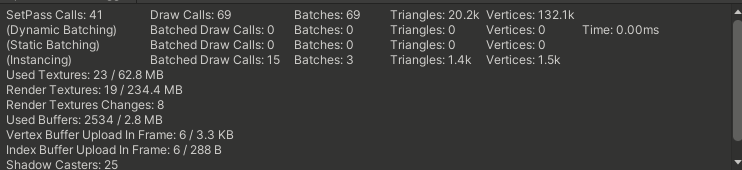
- 减少模型顶点,三角面数
- 减少或压缩纹理大小
资源加载和卸载
原型模式或prefab
享元模式或scriptableObject
享元模式方法记录:把共享的数据抽象出来,可以是一个类,再将该类的唯一个对象的引用,注入到需要用该数据的对象类即可。
网络
安全
其余tricks
- 公共mono模块
- 引用传递避免复制
实践
又到了哥们最喜欢的实践环节
游戏介绍
是一款3D拼图游戏,没有任何优化,写的时候我纯无脑写的

有如下3大需求:
- 需要外接传感器,根据甲方要求的理论[^1]对其数据进行计算,得到的结果会实时改变游戏场景;
- 六边形网格地图
- 3个场景
下面是具体的优化过程
性能优化
先看脚本和算法改进
发现写的动态生成六边形网格算法本身就两问题
生成网格时有时会重复生成,回退时退不完全
改进方法:加入了六边形网格坐标,确保生成回退准确
六边形数据结构体
Hexagon是不变的,却由六边形类重复生成1
2
3
4
5public class HexCell : MonoBehaviour{
Hexagon hex;
void Start()
hex = new Hexagon(transform.position.x,transform.position.z);
}改进方法:享元模式
对传感器数据处理的改进
理论是需要用贝叶斯网络模型来计算的,得到的结果是几个情绪等级。
这里偷了个懒:我把所有的输入的可能匹配结果先在
Netica里计算了出来,再把匹配关系逻辑写在了脚本里,从而省去了构建一个贝叶斯网络模型的计算过程,姑且算是个优化🤥🤥🤥🤥🤥。有多个重复利用的游戏对象(一块块拼图)
改进方法:建立缓存池
再看Profiler
看GC分配发现以下几个地方存在问题



看运行时间
发现Playerloop消耗时间最大3ms,正常在1-2ms之间,消耗最大的是鼠标点击事件
FindMainCameraCall就是由于调用了Camera.main。
再看游戏Ui优化
ui优化目的主要是尽量合批ui,减少drawcall,这里我们通过Stats视窗可以看到ui的批次
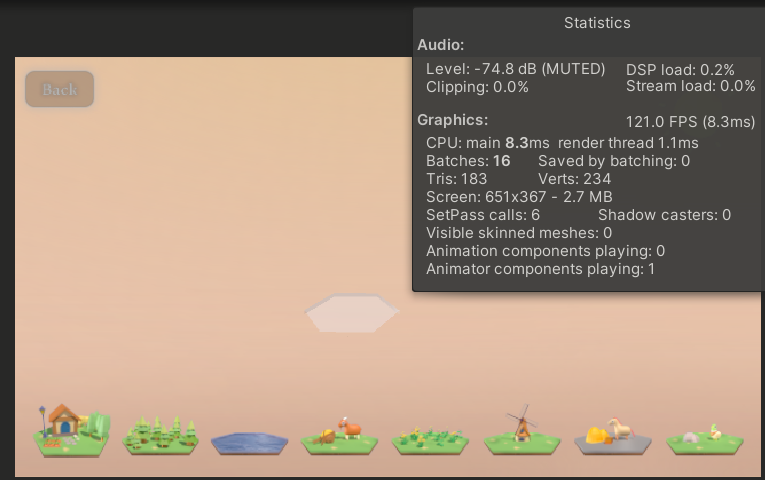

可以看到Batches的区别正好就是9个Button,所以可以将其合批,这里通过打图集的方式;
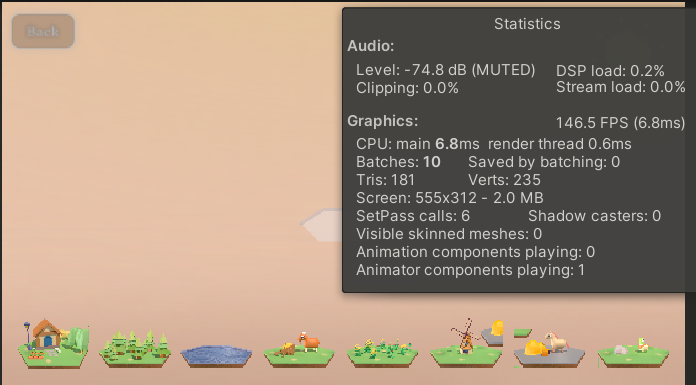
可以看到batches是10,因为Back放在了共享图集,其他由于Size的原因分为了两个图集,所以正好是10
场景渲染优化
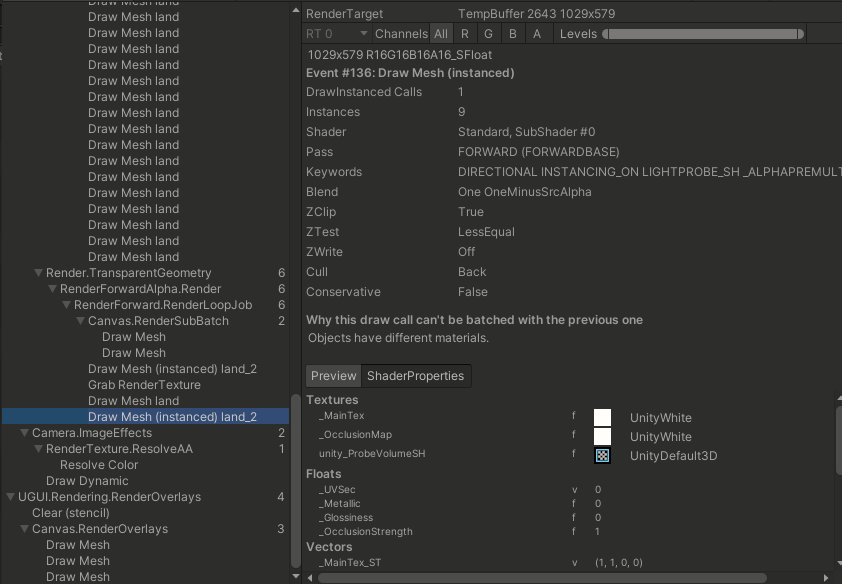
这是一个有五个物体场景stats信息
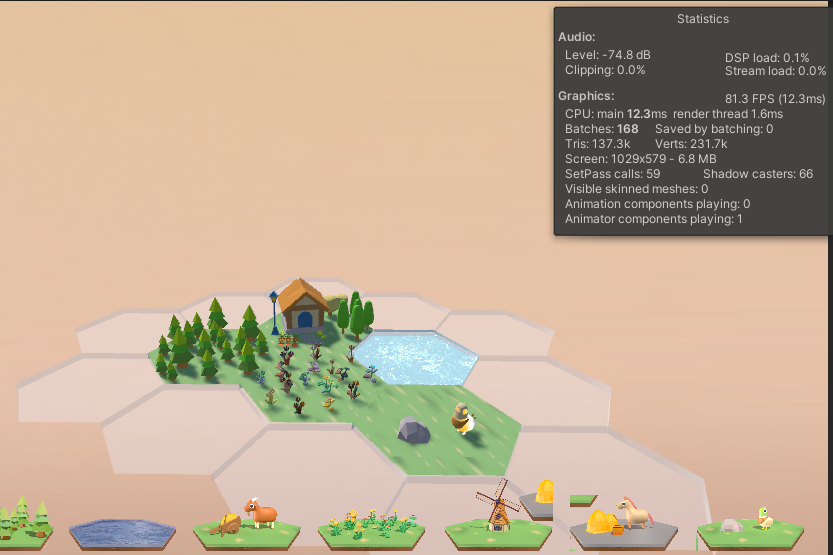
选择合适合批技术,这里最符合的是GPU Instancing技术,应用之后Saved by batching是33.
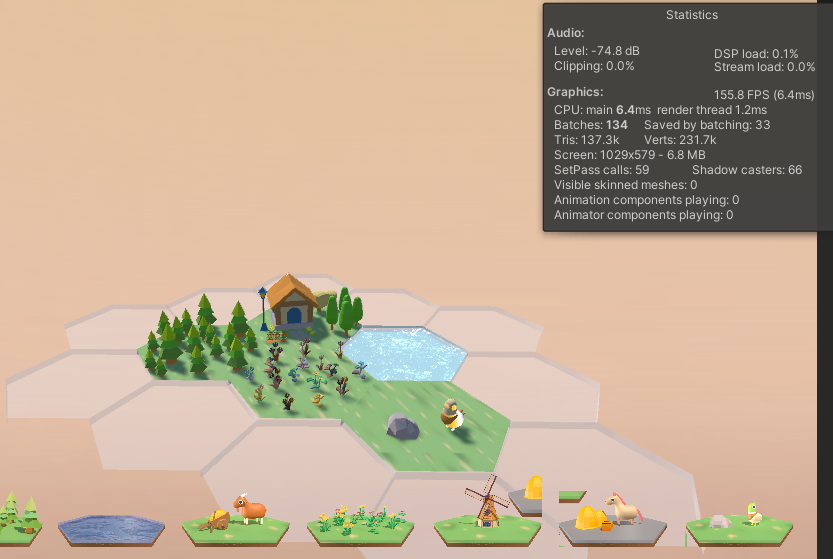
通过Frame Debugger可以详细的看到Gpu Instancing帮我们合批的结果,拥有相同材质和网格的模型被合批渲染
内存优化
把多余无用的素材删除(尽管unity打包时会忽略不在资源路径下的多余文件)
尽量减少贴图大小
如
Generate Mip Maps,Read/Write Enabled在需要时再启用尽量保证材质球,贴图复用性
在导入模型时,由于操作不规范,致使unity自动导入了部分重复贴图创建了重复材质球,也有一部分模型原因。
所以要删除这些重复资源,在三个不同场景中可复用的材质球也需复用,不但减小内存,也对渲染优化有帮助
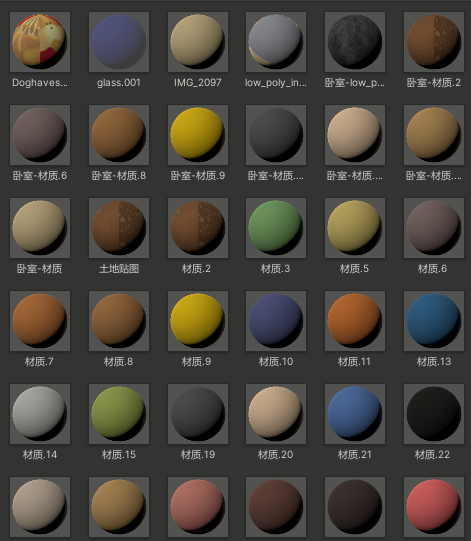
总共删了200mb上下的材质贴图资源。
减小模型面片数
打开
Scene的WireFrame渲染模式,发现模型面片数雀氏可以优化,比如基底六边形面片可以只由4个三角形构成,我就可以选择用unity网格绘制算法,至于其他的模型,就只能找模型师傅了。

包体优化
把Resources文件下的多余文件删掉,也可以改用AssetBundle热加载以减小包头大小。
参考:
[^1]: https://www.researchgate.net/publication/229060009_Emotion_recognition_from_electromyography_and_skin_conductance Emotion recognition from electromyography and skin conductance